대학소개
입학·국제교류
대학·대학원
대학생활
산학·연구
취업·창업
정보·민원서비스
| 제목 | 인공지능응용학과 김한울 교수 연구팀, CV/AI 분야 Top Conference “CVPR 2026” 논문 발표 | ||||
|---|---|---|---|---|---|
| 작성자 | 홍보실 | 조회수 | 139 | 날짜 | 2026-06-11 |
| 첨부파일 |
|
||||
|
▲ (좌측부터) 송채영 학석사연계과정생, 지도교수 김한울
창의융합대학 인공지능응용학과 김한울 교수 연구팀이 CV/AI 분야 최고 권위 국제학술대회인 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR) 2026에서 연구 논문을 발표했다.
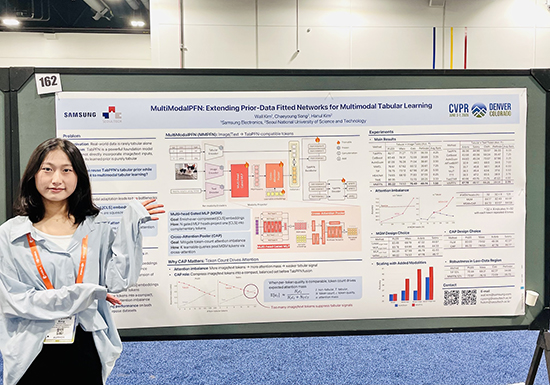
먼저 「MultiModalPFN: Extending Prior-Data Fitted Networks for Multimodal Tabular Learning」 논문은 정형 데이터 기반 파운데이션 모델인 TabPFN을 이미지와 텍스트가 함께 존재하는 실제 데이터 환경으로 확장하는 새로운 멀티모달 학습 방법론을 제안한다.
김한울 교수 연구팀은 기존 정형 데이터 파운데이션 모델을 멀티모달 환경으로 확장하는 과정에서 발생하는 핵심 한계로, 이미지·텍스트 표현이 하나의 임베딩으로 과도하게 압축되는 문제와 비정형 데이터 토큰 수 증가에 따라 정형 데이터 신호가 약화되는 attention imbalance 문제를 규명했다. 이를 해결하기 위해 Multi-Modal Prior-data Fitted Network(MMPFN)를 제안하고, 정형 데이터와 이미지·텍스트 정보를 TabPFN이 함께 처리할 수 있는 정형 데이터 호환 토큰으로 변환하는 구조를 설계했다.
특히 Multi-head Gated MLP(MGM)를 통해 압축된 이미지·텍스트 표현으로부터 다양한 비정형 정보 토큰을 생성하고, Cross-Attention Pooler(CAP)를 통해 생성된 토큰을 균형 있게 압축함으로써 attention imbalance 문제를 완화했다. 실험 결과, MMPFN은 의료 및 일반 목적 멀티모달 데이터셋에서 기존 주요 방법론 대비 우수한 성능을 보였으며, 제한된 학습 데이터 환경에서도 안정적인 성능을 유지해 데이터 확보가 어려운 산업 및 의료 응용 분야에서도 효과적인 멀티모달 학습 대안이 될 수 있음을 보였다.
또한 김한울 교수 연구팀은 충남대학교 연구팀과의 협업을 통해 「EG-3DVG: E xpression and Geometry Aware Grounding Decoder for 3D Visual Grounding」 논문을 발표했다. 본 연구는 자연어 표현을 기반으로 3D 장면 속 대상 객체를 정확히 찾는 3D Visual Grounding 문제를 다루며, 텍스트와 3D 시각 정보의 정렬 및 공간·기하 정보 활용을 개선하는 grounding decoder를 제안했다. 제안 방법은 주요 3D Visual Grounding 벤치마크에서 우수한 성능을 보여, 로보틱스·자율주행 등 3D 공간 이해가 필요한 분야에서의 활용 가능성을 확인했다.
|
|||||

 담당부서 : 홍보실
담당부서 : 홍보실
 전화번호: 02-970-6994
전화번호: 02-970-6994