


대학소개
입학·국제교류
대학·대학원
대학생활
산학·연구
취업·창업
정보·민원서비스
| 제목 | 산업공학과/데이터사이언스학과 권혁윤 교수 연구팀, 데이터베이스/데이터엔지니어링 분야 Top Conference IEEE ICDE2025, ACM SIGMOD2025 논문 발표 | ||||
|---|---|---|---|---|---|
| 작성자 | 홍보실 | 조회수 | 23163 | 날짜 | 2025-07-02 |
| 첨부파일 |
|
||||
|
산업공학과/데이터사이언스학과 빅데이터 주도 인공지능 (Big Data-Driven Artificial Intelligence) 연구실(지도교수: 권혁윤, http://bigdata.seoultech.ac.kr)은 데이터베이스 및 데이터엔지니어링 분야 Top Conference인 IEEE ICDE2025 (2025년 5월, 홍콩)와 ACM SIGMOD2025 (2025년 6월, 독일 베를린)에서 논문을 발표하였다.
각 논문은 데이터사이언스 학과 소속 석사과정인 문지훈 학생과 임보영 학생이 제1저자로 발표하였으며, 문지훈 학생은 Georgia Tech의 Ling Liu 교수, 임보영 학생은 Louisiana State University의 Kisung Lee 교수와 국제 공동연구를 통해 결과를 도출하였다
두 편의 논문은 한국정보과학회 컴퓨터종합학술대회 2025 Top Conference Session과 데이터지능워크샵 2025의 Future Star Researchers와에 초대되어 발표된다.
• 데이터지능워크샵 2025의 Future Star Researchers: https://dbsociety.kr/diworkshop/2025/program.html
• 한국정보과학회 컴퓨터종합학술대회 2025 Top Conference Session: https://www.kiise.or.kr/conference/main/getContent.do?CC=kcc&CS=2025&content_no=2278&PARENT_ID=011600
논문1: 클라이언트의 특성을 모델에 동적으로 반영하는 개인화된 연합학습 방법론 연구
• 제목: FedSDP: Federated Self-Derived Prototypes for Personalized Federated Learning
• 발표학회: 41st IEEE International Conference on Data Engineering (ICDE 2025)
• 저자: Jihoon Moon (SeoulTech), Ling Liu (Georgia Tech), Hyuk-Yoon Kwon (SeoulTech)
• Indexed: 한국연구재단 공인 BK 우수학술대회 (IF=3), 2024년 정보과학회 최우수학술대회
• 공헌요약: FedSDP는 개인화와 일반화의 균형을 동적으로 조정하는 새로운 PFL 프레임워크를 제안한다. 공유 바디와 개인화 헤드 사이에 브리지 레이어를 삽입하여, 각 클라이언트가 자체적으로 도출한(Self-Derived) 프로토타입을 기반으로 학습을 수행한다. 이를 위해 GL-Sim Weight와 P-Stop Indicator라는 두 가지 동적 조정 기법을 도입하여 학습 중 개인화 수준과 일반화 집중 시점을 제어한다. 실험을 통해 non-IID 환경에서도 안정적인 성능과 기존 SOTA 모델 대비 향상된 결과를 나타낸다.
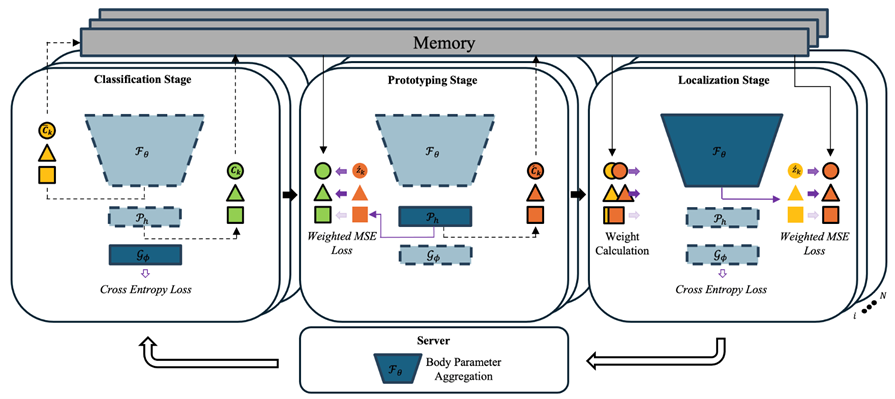 * 본 연구는 BK21 서울과학기술대학교 데이터사이언스와 비즈니스포텐션 교육연구단과 연구재단 (2025 중견연구)의 지원을 받아 수행되었다.
논문2: 예측에 기반한 다층 분할을 통한 그래표 표현 학습 방법론 연구
• 제목: Multi-Level Graph Representation Learning Through Predictive Community-b ased Partitioning
• 발표학회: ACM International Conference on Management of Data (SIGMOD 2025)
• 저자: Bo-Yong Lim (SeoulTech), Jeong-Ha Park (SeoulTech), Kisung Lee (LSU), Hyuk-Yoon Kwon (SeoulTech)
• Indexed: 한국연구재단 공인 BK 우수학술대회 (IF=4, 최상위), 2024년 정보과학회 최우수학술대회
• 공헌요약: 본 논문에서 제안하는 ML-GRL은 예측 모델을 사용하여 그래프에 적합한 커뮤니티 탐지 알고리즘을 선택하면서 서브그래프로 재귀적으로 파티셔닝하고, 서브그래프 간 관계구조를 활용해 서브그래프의 크기에 따라 구분된 그래프 표현 학습 방식을 수행함으로써 정확도와 학습 효율성 모두를 극대화 할 수 있다. 또한, 그래프 표현 학습 모델의 종류에 관계없이 범용적으로 적용할 수 있는 그래프 표현 학습 방법론 제안하였다. 기존 방법론들과의 다양한 비교실험을 통해 제안하는 방법론이 표현 정확도와 학습 효율성 두 가지 측면에서 성능을 향상시킬 수 있음을 보였다.
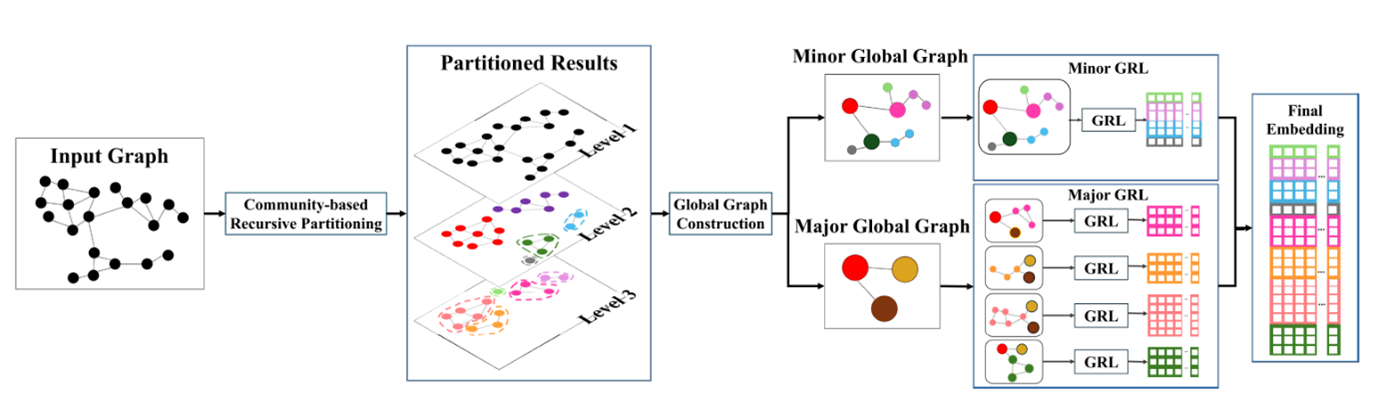 * 본 연구는 BK21 서울과학기술대학교 데이터사이언스와 비즈니스포텐션 교육연구단과 연구재단 (2025 중견연구)의 지원을 받아 수행되었다.
|
|||||

 담당부서 : 홍보실
담당부서 : 홍보실
 전화번호: 02-970-6994
전화번호: 02-970-6994





